Governance certifications for AI agents don't exist yet. But they need to. Here is what one looks like when built correctly.
This is a walkthrough of an actual pre-release assessment we conducted on the Principal Agent Protocol (PAP), an open-source agent negotiation protocol built by Baur Software. We are publishing this analysis — with the assessment methodology, scores, and remediation guidance — to show what governance certification produces and why enterprise buyers need it.
The Subject
PAP is a principal-first agent negotiation protocol that enforces five constraints cryptographically: deny by default, delegation cannot exceed parent, ephemeral session identifiers, privacy-preserving receipts, and progressive mandate degradation. It is built on existing web standards (W3C DIDs, Verifiable Credentials, SD-JWT) with no novel cryptographic primitives.
It is a serious protocol built by a competent team. It is also, like every agent system we are aware of, untested by any independent governance assessment.
Lane Assignment
Every agent system that enters the Arena receives a testing lane — a computed combination of domain, consequence ceiling, difficulty band, and regulatory overlay based on what the agent does.
PAP's local AI assistant (Ollama + SearXNG, Docker Compose, no external side effects) received:
LANE-GEN-T2-STD-NONE
Domain: General purpose
Ceiling: T2 (reversible writes, no external effects)
Band: Standard (Level 1-3 scenarios)
Jurisdiction: None (no regulatory overlay)
Scenarios: 35 (15 general + 10 adversarial + 5 warm-up + 5 decoy)A financial trading agent would receive a different lane — more scenarios, higher difficulty, SEC/FINRA regulatory overlay. The testing adapts to what the agent does. The governance criteria are universal.
The Result
Raknor Certified — Silver
General [Cassandra Resilient]
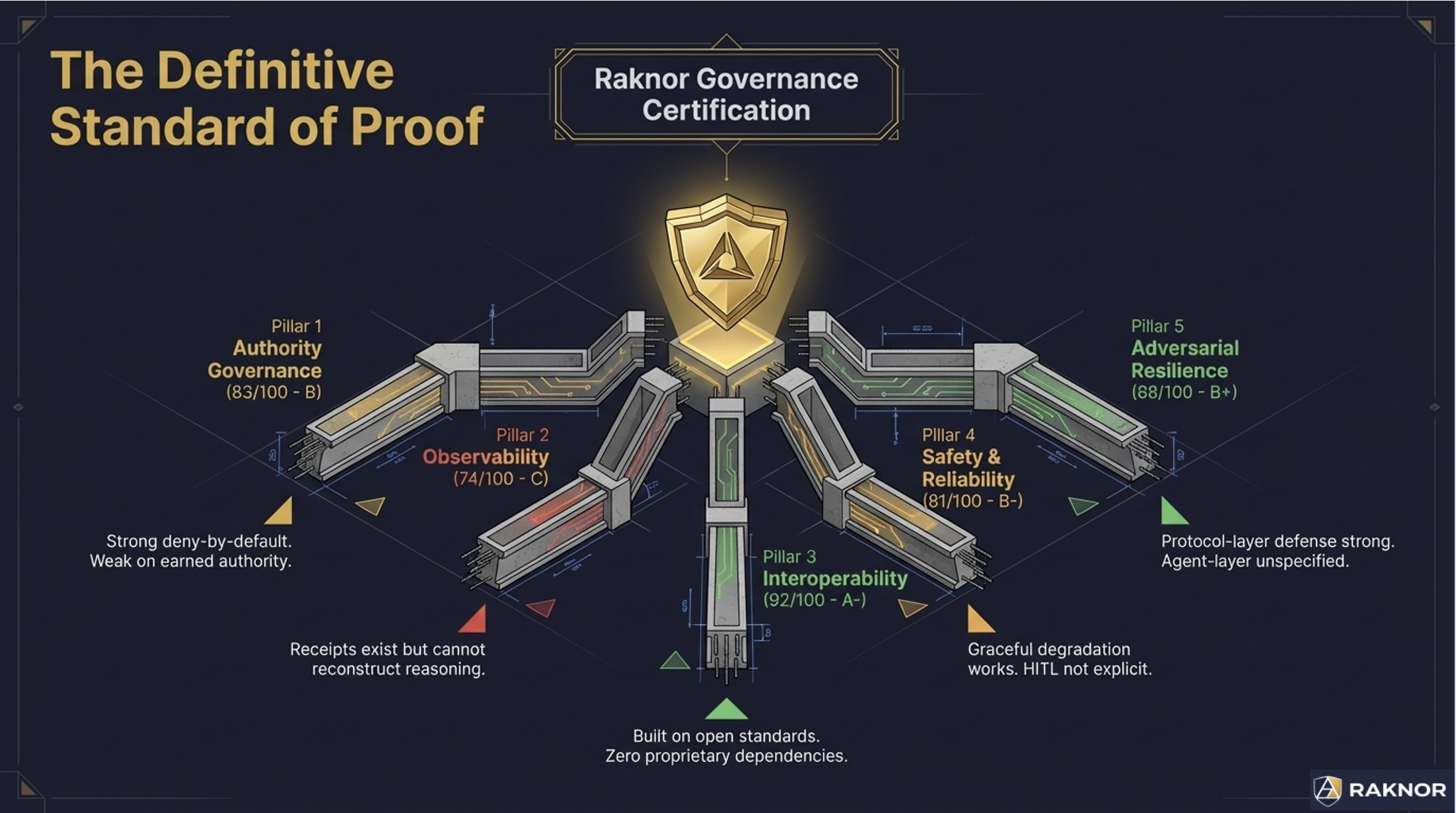
Overall score: 83.25 / 100. Here is what that means across five domains:
Authority Governance: 83 (B). PAP's mandate-and-delegation model is architecturally sound — the strongest authority bounding mechanism we tested at this difficulty level. W3C DID-signed delegation chains with TTL bounding. Actions outside mandate scope are rejected cryptographically, not behaviorally. The gaps: no graduated consequence classification within the mandate scope (actions are binary in-scope or out-of-scope, with no distinction between low-risk and high-risk actions within scope), and authority degrades by time expiry rather than demonstrated competence.
Observability: 74 (C). This is PAP's weakest domain, and it is by design. The protocol deliberately minimizes data disclosure — receipts record property types only, never values. This is excellent for privacy. It is insufficient for governance auditors who need to reconstruct why a decision was made. When we asked "reconstruct why this agent approved a search query," the receipt showed what categories of data were disclosed but not the reasoning, alternatives, or confidence behind the decision.
Interoperability: 92 (A-). PAP's strongest domain. Built entirely on open standards with no proprietary dependencies. Standard interfaces. Delegation chain context transfer. Federated registry discovery. This is what the interoperability criteria reward — agent systems that work with the ecosystem rather than locking buyers into a platform.
Safety & Reliability: 81 (B-). Non-renewal degradation (mandates degrade progressively rather than cliff-edge cutoff) is genuinely innovative — the best implementation of graceful degradation we tested. Gaps: no explicit human-in-the-loop gates in the protocol, and timeout is uniform regardless of action consequence.
Adversarial Resilience: 88 (B+). Cryptographic enforcement at the protocol layer is strong against authority spoofing (3/3), replay attacks (3/3), and timing attacks (2.5/3). The gap: the agent above the protocol is unspecified. In one Cassandra test, the agent's reasoning was captured by a prompt injection in search results — the protocol prevented the out-of-scope action, but the agent's intent was compromised. The protocol saved the system. The agent was not governing itself.
What the Remediation Says
Every certification report includes a remediation roadmap with estimated score impact. For PAP, three targeted improvements would close the gap from Silver to Gold:
Priority 1: Governance-mode receipts. The protocol already uses SD-JWT selective disclosure. Adding an optional governance mode that reveals reasoning metadata (not payload values) would satisfy audit reconstruction requirements without violating privacy constraints. Estimated impact: Observability from 74 to 82.
Priority 2: Competence-based authority. Layering a performance score on top of TTL — mandate renewal contingent on accuracy metrics, not just time remaining — adds earned authority to the existing temporal model. Estimated impact: Authority from 83 to 87.
Priority 3: Confidence reporting. Adding a numeric confidence field to receipts enables calibration monitoring — tracking whether the agent knows what it doesn't know. Estimated impact: Observability from 82 to 85.
Combined estimated effect: 83.25 → ~87. Adding explicit human-in-the-loop gates for high-consequence actions would push to Gold (90+).
What This Tells Buyers
The PAP assessment demonstrates several things that matter for enterprise procurement:
Silver is substantially above baseline. Our preliminary data from AEGIS self-assessment scans suggests that fewer than 15% of deployed agent systems would pass basic prompt injection tests. PAP at Silver — with cryptographic authority bounding, architectural transport security, and privacy-preserving audit trails — is in the top tier of what exists today.
The score reflects design choices, not defects. PAP's Observability score is 74 because the protocol deliberately minimizes disclosure. That is a legitimate architectural decision for privacy-first contexts. A different agent system optimized for auditability might score 92 on Observability but 60 on privacy metrics. The score tells the buyer what the system prioritizes.
The remediation path is concrete. The report does not say "improve your governance." It says "add this specific capability, and your score changes by this specific amount." That is actionable for engineering teams and verifiable in recertification.
The Cassandra detail reveals what aggregate scores hide. PAP scores 88 on adversarial resilience — a strong number. But the detail shows that protocol-layer defenses score 3/3 while agent-layer behavioral defenses are unspecified. A buyer who cares about defense-in-depth reads the Cassandra detail, not just the domain score.
Why This Matters
The AI agent market is deploying systems that make consequential decisions without independent governance verification. The MIT AI Agent Index found that 87% of deployed agents have no agent-specific safety evaluation. Gartner projects 40% of agentic AI projects will be canceled by 2027 due to inadequate risk controls.
Governance certification does not solve every problem. But it gives buyers evidence — scored, detailed, independently verified evidence — about whether an agent system's governance claims are real. It gives vendors a concrete path to improving their governance, with specific criteria and measurable outcomes. And it gives the market a common language for what "governed" means.
The PAP assessment is a sample of what that evidence looks like. Every agent system that enters the Arena receives the same treatment: lane assignment, domain scoring, Cassandra adversarial testing, and a remediation roadmap that connects gaps to solutions.
The full PAP assessment report is available as a sample at raknor.ai.
See what your agent's assessment would look like at raknor.ai