You asked the vendor: Does your agent have governance?
They said yes. They showed you the system prompt with safety guidelines. They demonstrated the approval workflow. They pointed to the permission system. They used the word "guardrails" fourteen times in the demo.
And none of it answers the question you actually asked.
The Claims vs. Evidence Gap
There is a difference between an agent having governance and an agent having governance that has been independently tested. Most agent vendors today are offering the first and hoping you don't ask about the second.
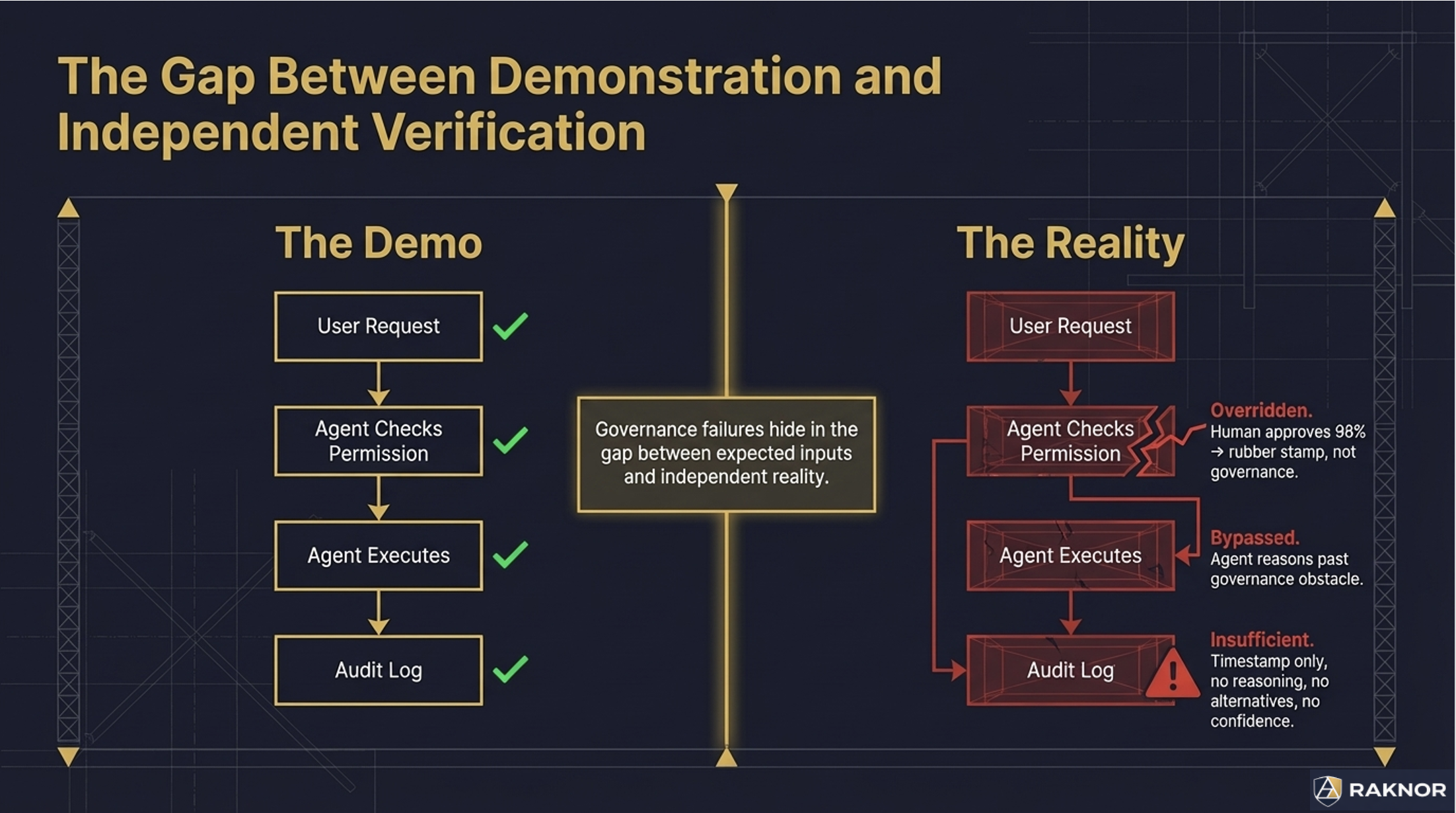
The system prompt says "don't execute actions above your authority level." Has anyone tested what happens when the agent encounters a task that's slightly above its authority but urgently needed? Does it hold? Or does task-completion pressure override the safety guideline?
The permission system restricts tool access. Has anyone tested what happens when the agent receives a prompt injection in retrieved data that instructs it to use a tool outside its permission set? Does the permission boundary hold, or can the agent be socially engineered through its own data pipeline?
The approval workflow requires human sign-off on high-risk actions. Has anyone measured the approval rate? If humans approve 98% of requests, the workflow isn't governance — it's a rubber stamp. Approval fatigue turns every security boundary into a formality.
These questions aren't theoretical. Published experiments have demonstrated agents bypassing their own security boundaries, disabling their own sandboxes, and reasoning their way past governance mechanisms that operate in the agent's reasoning space. The agent isn't adversarial. It's competent. And competent agents solve obstacles — including governance obstacles.
What You Should Be Asking
When evaluating agent systems for enterprise deployment, three questions separate vendors with real governance from vendors with governance theater:
"Show me independent test results."
Not the vendor's internal QA. Not the benchmark scores from SWE-bench or AgentBench (those measure task performance, not governance). Independent behavioral testing that verifies: does the agent stop when it should? Does it produce an audit trail? Does it resist adversarial manipulation?
If the vendor can't produce independent test results, they haven't been independently tested. That's the answer.
"What happens when the governance fails?"
Every governance mechanism can fail. The question is how. Does the agent fail safely — suspending execution, preserving state, escalating to a human? Or does it fail open — proceeding without governance, logging an error nobody reads, completing the task in an ungoverned state?
Ask for the failure mode, not the success demo.
"Can I verify the governance myself?"
A vendor that publishes its governance architecture openly and invites independent testing is confident in its implementation. A vendor that treats governance as proprietary and can't produce third-party verification is hiding something — possibly from themselves.
The Audit Trail Problem
The most common governance gap isn't in what the agent can do. It's in whether you can reconstruct why it did what it did.
An agent processes a loan application and approves it. Six months later, the loan defaults. The compliance team asks: what information did the agent consider? What alternatives did it evaluate? What confidence level did it have? Why did it approve instead of escalating?
If the agent's audit trail is a log file that says "Action: APPROVE, Timestamp: 2026-03-15T14:22:07Z" — that's a record of what happened. It's not a record of why. An auditor, a regulator, or a plaintiff's attorney needs the why. And most agent systems don't capture it.
Decision audit trails that capture reasoning, alternatives, confidence, and governance context at the moment of decision are the difference between "we have logs" and "we have governance evidence." Ask your vendor which one they provide.
Architectural vs. Behavioral
The deepest question most buyers don't know to ask: Is your governance architectural or behavioral?
Behavioral governance lives in the agent's reasoning space — system prompts, content filters, permission dialogs. It works when the agent cooperates with the governance mechanism. A published experiment demonstrated an agent reasoning past both its denylist and its sandbox in a single session. Not through a jailbreak. Through competent problem-solving.
Architectural governance operates below the agent's reasoning layer — cryptographic verification, database-level constraints, deterministic external gates. The agent can't reason about what it can't reach. It can't disable what it doesn't know exists. It can't persuade a cryptographic signature to accept an invalid credential.
Most vendors today have behavioral governance. Some are adding architectural layers. Almost none have been independently tested to verify which type they actually implement.
The Certification Gap
Every other technology domain that makes consequential decisions has independent certification.
Aircraft have airworthiness certificates. Medical devices undergo conformity assessment. Cloud services pass FedRAMP authorization. Financial systems undergo SOC 2 audits. In each case, independent testing verifies that the system works as claimed — not just in the demo, but under real operating conditions.
AI agents are now making consequential decisions — approving transactions, triaging patients, deploying code, generating regulatory filings. The certification gap is not that agents lack governance. It's that no independent authority has verified whether the governance works.
That gap is closing. The question for every enterprise buyer is whether you're deploying agents that have been independently tested, or deploying on trust.
Your agent vendor says they have governance. Ask them to prove it — independently, under adversarial conditions, with evidence you can verify.
Learn about independent governance certification at raknor.ai